线程
- CPU上的执行单位,线程也是程序运行过程中的一个抽象。
- 一个进程下可以有多个线程。
- 主线程:操作系统中的每一个进程都会对应一个地址空间。每一个进程中都会默认有一个控制线程,主线程随着进程的创建而出现。所以一个进程中主线程存在就代表了这个进程的存在,当进程中的主线程结束的时候,操作系统就会将该进程回收
有了进程为什么还要线程?
进程有很多优点,它提供了多道编程,让我们感觉我们每个人都拥有自己的CPU和其他资源,可以提高计算机的利用率。很多人就不理解了,既然进程这么优秀,为什么还要线程呢?其实,仔细观察就会发现进程还是有很多缺陷的,主要体现在两点上:
- 进程只能在一个时间干一件事,如果想同时干两件事或多件事,进程就无能为力了。
- 进程在执行的过程中如果阻塞,例如等待输入,整个进程就会挂起,即使进程中有些工作不依赖于输入的数据,也将无法执行。
例如,我们在使用qq聊天, qq做为一个独立进程如果同一时间只能干一件事,那他如何实现在同一时刻 即能监听键盘输入、又能监听其它人给你发的消息、同时还能把别人发的消息显示在屏幕上呢?你会说,操作系统不是有分时么?但是分时是指在不同进程间的分时, 即操作系统处理一会你的qq任务,又切换到word文档任务上了,每个cpu时间片分给你的qq程序时,事实上,你的qq还是同一时间只能干一件事情。
再直白一点, 一个操作系统就像是一个工厂,工厂里面有很多个生产车间,不同的车间生产不同的产品,每个车间就相当于一个进程,且你的工厂又穷,供电不足,同一时间只能给一个车间供电,为了能让所有车间都能同时生产,你的工厂的电工只能给不同的车间分时供电,但是轮到你的qq车间时,发现只有一个干活的工人,结果生产效率极低,为了解决这个问题,就需要多加几个工人,让几个人工人并行工作,这每个工人,就是线程!
线程的特点
在多线程的操作系统中,通常是在一个进程中包括多个线程,每个线程都是作为利用CPU的基本单位,是花费最小开销的实体。线程具有以下属性。
1)轻型实体
线程中的实体基本上不拥有系统资源,只是有一点必不可少的、能保证独立运行的资源。
线程的实体包括程序、数据和TCB。线程是动态概念,它的动态特性由线程控制块TCB(Thread Control Block)描述。
2)独立调度和分派的基本单位
在多线程OS中,线程是能独立运行的基本单位,因而也是独立调度和分派的基本单位。由于线程很“轻”,故线程的切换非常迅速且开销小(在同一进程中的)。
3)共享进程资源
线程在同一进程中的各个线程,都可以共享该进程所拥有的资源,这首先表现在:所有线程都具有相同的进程id,这意味着,线程可以访问该进程的每一个内存资源;此外,还可以访问进程所拥有的已打开文件、定时器、信号量机构等。由于同一个进程内的线程共享内存和文件,所以线程之间互相通信不必调用内核。
4)可并发执行
在一个进程中的多个线程之间,可以并发执行,甚至允许在一个进程中所有线程都能并发执行;同样,不同进程中的线程也能并发执行,充分利用和发挥了处理机与外围设备并行工作的能力。
TCB包括以下信息:
(1)线程状态。
(2)当线程不运行时,被保存的现场资源。
(3)一组执行堆栈。
(4)存放每个线程的局部变量主存区。
(5)访问同一个进程中的主存和其它资源。
用于指示被执行指令序列的程序计数器、保留局部变量、少数状态参数和返回地址等的一组寄存器和堆栈。
进程和线程的区别
- 线程是共享内存空间的;进程的内存是独立的。
- 线程可以直接访问此进程中的数据部分;进程有他们独立拷贝自己父进程的数据部分,每个进程是独立的
- 同一进程的线程之间直接交流(直接交流涉及到数据共享,信息传递);两个进程想通信,必须通过一个中间代理来实现。
- 创建一个新的线程很容易;创建新的进程需要对其父进程进行一次克隆。
- 一个线程可以控制和操作同一进程里的其他线程;但是进程只能操作子进程。
- 对主线程的修改,可能会影响到进程中其他线程的修改;对于一个父进程的修改不会影响其他子进程(只要不删除父进程即可)
疑问
进程和线程那个运行快?
它俩是没有可比性的,线程是寄生在进程中的,你问它俩谁快。说白了,就是问在问两个线程谁快。因为进程只是资源的集合,进程也是要起一个线程的,它俩没有可比性。
进程和线程那个启动快?
答案是:线程快。因为进程相当于在修一个屋子。线程只是一下把一个来过来就行了。进程是一堆资源的集合。它要去内存里面申请空间,它要各种各样的东西去跟OS去申请。但是启动起来一运行,它俩是一样的,因为进程也是通过线程来运行的。
自己理解
- 线程是操作系统最小的调度单位,是一串指令的集合。
- 进程要操作CPU,必须先创建一个线程。
- 进程本身是不可以执行的,操作cpu是通过线程实现的,因为它是一堆执行,而进程是不具备执行概念的。就像一个屋子,屋子就是进程,但是屋子里面的每一个人就是线程,屋子就是内存空间。
- 单核CPU只能同时干一件事,但是为什么给我们的感觉是在干了很多件事?因为上线的切换,刚才也说了跟读书那个例子一样。因为CPU太快了,可以有N多次切换,其实它都是在排着队呐。
- 寄存器是存上下文关系的。
- 进程是通过PID来区分的,并不是通过进程名来区分的。进程里面的第一个线程就是主线程,父线程和子线程是相互独立的,只是父线程创建了子线程,父线程down了,子线程不会受到影响的。
- 主线程修改影响其他线程的行文,因为它们是共享数据的。
线程的创建Threading.Thread类
线程的创建
1 | from threading import Thread |
1 | from threading import Thread |
多线程与多进程
pid的比较
1 | from threading import Thread |
开启效率的较量
1 | from threading import Thread |
内存数据的共享问题
1 | from threading import Thread |
上面的例子中最多只启动了一个2个线程,还是用那种古老的方式t1,t2。要是一下子起10个或者100个线程,这种方式就不适用了,其实可以在启动线程的时候,把它加到循环里面去,并且来计算一下它的时间 :
1 | import threading,time |
这里设置成启动5个线程,并且计算一下时间。这里有个疑问,为什么不启动1000个线程或者更多一点的线程?这是因为:计算机是4核的,它能干的事情,就是4个任务。启动的线程越多,就代表着要在这个很多线程之间进行上下文切换。相当于教室里有一本书,某个人只看了半页,因为cpu要确保每个人都能执行,也就是这本是要确保教室每个同学都能看到,那就相当于每个人看书的时间非常少。也就是说某个同学刚刚把这本书拿过来,一下子又被第二个人,第三个人拿走了。所以就导致所有的人都慢了,所以说如果线程启动1000就没有意义了,导致机器越来越慢,所以要适当设置
从上面的程序发现,就是我主线程没有等其他的子线程执行完毕,就直接往下执行了,这是为什么呢?而且这个计算的时间根本不是我们想要的时间,中间的sleep 2秒哪里去了?
其实一个程序至少有一个线程,那先往下走的,没有等的就是主线程,主线程启动了子线程之后,子线程就是独立的,跟主线程就没有关系了。主线程和它启动的子线程是并行关系,这就解释了为什么我的主线程启动子线程之后,没有等子线程,而继续往下走了。所以计算不出来线程总共耗时时间,因为程序已经不是串行的了。程序本身就是一个线程,就是主线程。如果要想测试这五个线程总共花了多长时间,就需要用到线程的join()方法
join
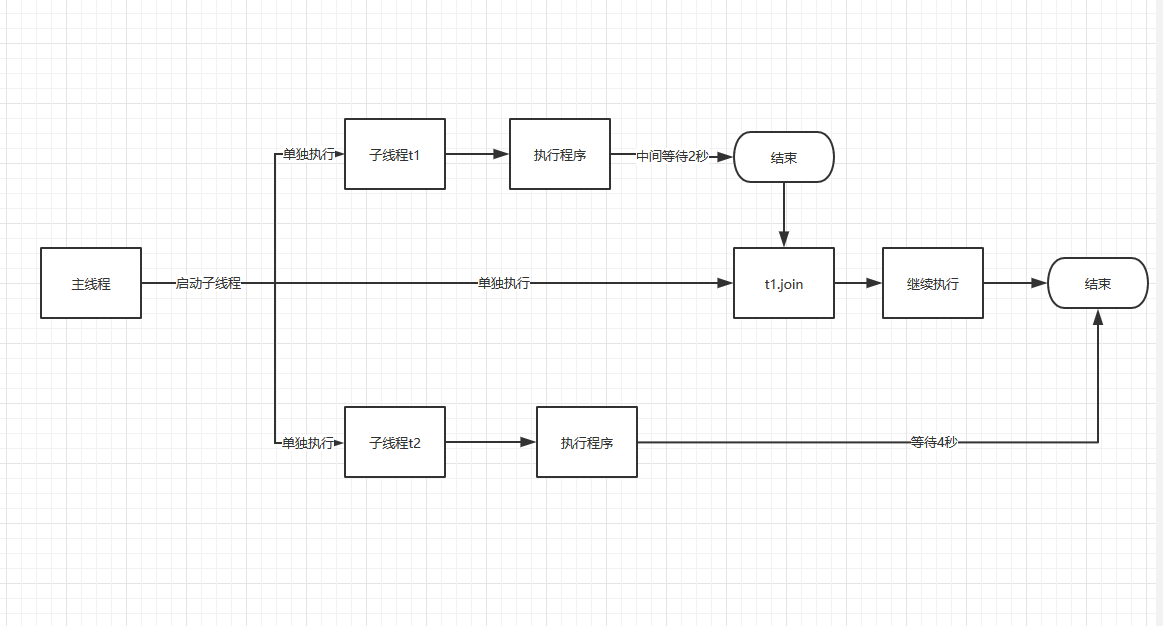
1 | import threading |
注意:t1.join() 只等t1的结果,然后主线程继续往下走,因为t2需要等4秒,所以,最后打出来的是t2的执行结果。t1的结果到了,就立刻算结果。这边只计算了t1的结果,没有t2的结果
那我们怎么计算多个线程的执行时间呢?来我们一起看一下:
1 | import threading |
上面的例子在不加join的时候,主线程和子线程完全是并行的,没有了依赖关系,主线程执行了,子线程也执行了。但是加了join之后,主线程依赖子线程执行完毕才往下走。 下面将介绍守护线程

