进程间通信
进程间通信有队列(multiprocess.Queue)和管道(multiprocess.Pipe),在这里只简单介绍队列
队列
概念介绍
创建共享的进程队列,Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递。
1 | Queue([maxsize]) |
方法介绍 :
q.get( [ block [ ,timeout ] ] )
返回q中的一个项目。如果q为空,此方法将阻塞,直到队列中有项目可用为止。block用于控制阻塞行为,默认为True. 如果设置为False,将引发Queue.Empty异常(定义在Queue模块中)。timeout是可选超时时间,用在阻塞模式中。如果在制定的时间间隔内没有项目变为可用,将引发Queue.Empty异常。
q.get_nowait( )
同q.get(False)方法。
q.put(item [, block [,timeout ] ] )
将item放入队列。如果队列已满,此方法将阻塞至有空间可用为止。block控制阻塞行为,默认为True。如果设置为False,将引发Queue.Empty异常(定义在Queue库模块中)。timeout指定在阻塞模式中等待可用空间的时间长短。超时后将引发Queue.Full异常。
q.qsize()
返回队列中目前项目的正确数量。此函数的结果并不可靠,因为在返回结果和在稍后程序中使用结果之间,队列中可能添加或删除了项目。在某些系统上,此方法可能引发NotImplementedError异常。
q.empty()
如果调用此方法时 q为空,返回True。如果其他进程或线程正在往队列中添加项目,结果是不可靠的。也就是说,在返回和使用结果之间,队列中可能已经加入新的项目。
q.full()
如果q已满,返回为True. 由于线程的存在,结果也可能是不可靠的(参考q.empty()方法)
q.close()
关闭队列,防止队列中加入更多数据。调用此方法时,后台线程将继续写入那些已入队列但尚未写入的数据,但将在此方法完成时马上关闭。如果q被垃圾收集,将自动调用此方法。关闭队列不会在队列使用者中生成任何类型的数据结束信号或异常。例如,如果某个使用者正被阻塞在get()操作上,关闭生产者中的队列不会导致get()方法返回错误。
q.cancel_join_thread()
不会再进程退出时自动连接后台线程。这可以防止join_thread()方法阻塞。
q.join_thread()
连接队列的后台线程。此方法用于在调用q.close()方法后,等待所有队列项被消耗。默认情况下,此方法由不是q的原始创建者的所有进程调用。调用q.cancel_join_thread()方法可以禁止这种行为。
实例
单看队列用法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28from multiprocessing import Queue
q = Queue(3)
# put ,get ,put_nowait,get_nowait,full,empty
q.put(3)
q.put(3)
q.put(3)
# q.put(3) # 如果队列已经满了,程序就会停在这里,等待数据被别人取走,再将数据放入队列。
# 如果队列中的数据一直不被取走,程序就会永远停在这里。
try:
q.put_nowait(3) # 可以使用put_nowait,如果队列满了不会阻塞,但是会因为队列满了而报错。
except: # 因此我们可以用一个try语句来处理这个错误。这样程序不会一直阻塞下去,但是会丢掉这个消息。
print('队列已经满了')
# 因此,我们再放入数据之前,可以先看一下队列的状态,如果已经满了,就不继续put了。
print(q.full()) # 满了
print(q.get())
print(q.get())
print(q.get())
# print(q.get()) # 同put方法一样,如果队列已经空了,那么继续取就会出现阻塞。
try:
q.get_nowait(3) # 可以使用get_nowait,如果队列满了不会阻塞,但是会因为没取到值而报错。
except: # 因此我们可以用一个try语句来处理这个错误。这样程序不会一直阻塞下去。
print('队列已经空了')
print(q.empty()) # 空了
上面这个例子还没有加入进程通信,只是先来看看队列为我们提供的方法,以及这些方法的使用和现象
子进程发送数据给父进程
1
2
3
4
5
6
7
8
9
10
11
12
13
14import time
from multiprocessing import Process, Queue
def func(q):
q.put([time.asctime(), 'from Eva', 'hello']) # 调用主函数中p进程传递过来的进程参数 put函数为向队列中添加一条数据。
if __name__ == '__main__':
q = Queue() # 创建一个Queue对象
p = Process(target=func, args=(q,)) # 创建一个进程
p.start()
print(q.get())
p.join()
上面是一个queue的简单应用,使用队列q对象调用get函数来取得队列中最先进入的数据
批量生产数据放入队列再批量获取结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33import time
import random
import os
from multiprocessing import Process, Queue
def consumer(q):
while True:
res = q.get()
time.sleep(random.randint(1, 3))
print('%s 吃 %s' % (os.getpid(), res))
def producer(q):
for i in range(10):
time.sleep(random.randint(1, 3))
res = '包子%s' % i
q.put(res)
print('%s 生产了 %s' % (os.getpid(), res))
if __name__ == '__main__':
q = Queue()
# 生产者们:即厨师们
p1 = Process(target=producer, args=(q,))
# 消费者们:即吃货们
c1 = Process(target=consumer, args=(q,))
# 开始
p1.start()
c1.start()
print('主')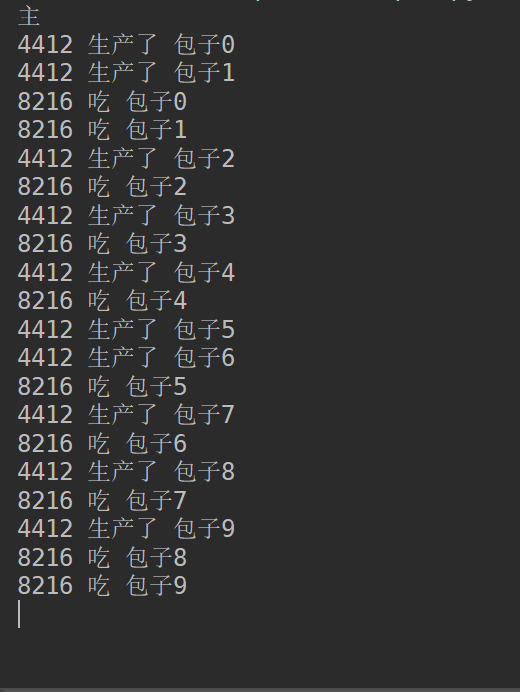
问题来了,我们看结果主进程永远不会结束,原因是:生产者p在生产完后就结束了,但是消费者c在取空了q之后,则一直处于死循环中且卡在q.get()这一步。
在解决上面问题之前,这里引入一个生产者消费者模型
生产者消费者模型
在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题。该模式通过平衡生产线程和消费线程的工作能力来提高程序的整体处理数据的速度
为什么要使用生产者和消费者模式
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
什么是生产者消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
要解决上面产生的问题无非是让生产者在生产完毕后,往队列中再发一个结束信号,这样消费者在接收到结束信号后就可以break出死循环
1 | from multiprocessing import Process, Queue |
注意:结束信号None,不一定要由生产者发,主进程里同样可以发,但主进程需要等生产者结束后才应该发送该信号
下面再看看多个消费者的例子:有几个消费者就需要发送几次结束信号
1 | from multiprocessing import Process, Queue |
有没有发现上面的方法很low,有几个消费者就要发送几次结束信号,下面再优化一下
1 | JoinableQueue([maxsize]) |
JoinableQueue的实例p除了与Queue对象相同的方法之外,还具有以下方法
方法介绍 :
q.task_done()
使用者使用此方法发出信号,表示q.get()返回的项目已经被处理。如果调用此方法的次数大于从队列中删除的项目数量,将引发ValueError异常。
q.join()
生产者将使用此方法进行阻塞,直到队列中所有项目均被处理。阻塞将持续到为队列中的每个项目均调用q.task_done()方法为止。
下面的例子说明如何建立永远运行的进程,使用和处理队列上的项目。生产者将项目放入队列,并等待它们被处理
1 | from multiprocessing import Process, JoinableQueue |
参考资料:
1 | http://www.cnblogs.com/Eva-J/articles/8253549.html |

